This course is a deep dive into the details of deep learning architectures with a focus on learning end-to-end models for these tasks, particularly image classification
This page contains my solutions and approaches for the assignment All source codes of my solutions are available on GitHub
Dropout
Dropout [1] is a technique for regularizing neural networks by randomly setting some output activations to zero during the forward pass. In this exercise, you will implement a dropout layer and modify your fully connected network to optionally use dropout.
=========== You can safely ignore the message below if you are NOT working on ConvolutionalNetworks.ipynb ===========
You will need to compile a Cython extension for a portion of this assignment.
The instructions to do this will be given in a section of the notebook below.
# Load the (preprocessed) CIFAR-10 data.data = get_CIFAR10_data()for k, v inlist(data.items()):print(f"{k}: {v.shape}")
In the file cs231n/layers.py, implement the forward pass for dropout. Since dropout behaves differently during training and testing, make sure to implement the operation for both modes.
Once you have done so, run the cell below to test your implementation.
def dropout_forward(x, dropout_param):""" Performs the forward pass for (inverted) dropout. Inputs: - x: Input data, of any shape - dropout_param: A dictionary with the following keys: - p: Dropout parameter. We keep each neuron output with probability p. - mode: 'test' or 'train'. If the mode is train, then perform dropout; if the mode is test, then just return the input. - seed: Seed for the random number generator. Passing seed makes this function deterministic, which is needed for gradient checking but not in real networks. Outputs: - out: Array of the same shape as x. - cache: tuple (dropout_param, mask). In training mode, mask is the dropout mask that was used to multiply the input; in test mode, mask is None.NOTE: Please implement **inverted** dropout, not the vanilla version of dropout. See http://cs231n.github.io/neural-networks-2/#reg for more details.NOTE 2: Keep in mind that p is the probability of **keep** a neuron output; this might be contrary to some sources, where it is referred to as the probability of dropping a neuron output. """ p, mode = dropout_param["p"], dropout_param["mode"]if"seed"in dropout_param: np.random.seed(dropout_param["seed"]) mask =None out =Noneif mode =="train":######################################################################## TODO: Implement training phase forward pass for inverted dropout. ## Store the dropout mask in the mask variable. ######################################################################### *****START OF YOUR CODE (DO NOT DELETE/MODIFY THIS LINE)***** mask = (np.random.rand(*x.shape) < p) / p out = x*mask# *****END OF YOUR CODE (DO NOT DELETE/MODIFY THIS LINE)*****######################################################################## END OF YOUR CODE ########################################################################elif mode =="test":######################################################################## TODO: Implement the test phase forward pass for inverted dropout. ######################################################################### *****START OF YOUR CODE (DO NOT DELETE/MODIFY THIS LINE)***** out = x# *****END OF YOUR CODE (DO NOT DELETE/MODIFY THIS LINE)*****######################################################################## END OF YOUR CODE ######################################################################## cache = (dropout_param, mask) out = out.astype(x.dtype, copy=False)return out, cache
np.random.seed(231)x = np.random.randn(500, 500) +10for p in [0.25, 0.4, 0.7]: out, _ = dropout_forward(x, {'mode': 'train', 'p': p}) out_test, _ = dropout_forward(x, {'mode': 'test', 'p': p})print('Running tests with p = ', p)print('Mean of input: ', x.mean())print('Mean of train-time output: ', out.mean())print('Mean of test-time output: ', out_test.mean())print('Fraction of train-time output set to zero: ', (out ==0).mean())print('Fraction of test-time output set to zero: ', (out_test ==0).mean())print()
Running tests with p = 0.25
Mean of input: 10.000207878477502
Mean of train-time output: 10.014059116977283
Mean of test-time output: 10.000207878477502
Fraction of train-time output set to zero: 0.749784
Fraction of test-time output set to zero: 0.0
Running tests with p = 0.4
Mean of input: 10.000207878477502
Mean of train-time output: 9.977917658761159
Mean of test-time output: 10.000207878477502
Fraction of train-time output set to zero: 0.600796
Fraction of test-time output set to zero: 0.0
Running tests with p = 0.7
Mean of input: 10.000207878477502
Mean of train-time output: 9.987811912159426
Mean of test-time output: 10.000207878477502
Fraction of train-time output set to zero: 0.30074
Fraction of test-time output set to zero: 0.0
Dropout: Backward Pass
In the file cs231n/layers.py, implement the backward pass for dropout. After doing so, run the following cell to numerically gradient-check your implementation.
def dropout_backward(dout, cache):""" Perform the backward pass for (inverted) dropout. Inputs: - dout: Upstream derivatives, of any shape - cache: (dropout_param, mask) from dropout_forward. """ dropout_param, mask = cache mode = dropout_param["mode"] dx =Noneif mode =="train":######################################################################## TODO: Implement training phase backward pass for inverted dropout ######################################################################### *****START OF YOUR CODE (DO NOT DELETE/MODIFY THIS LINE)***** p = dropout_param["p"] masked_gradients = dout*mask dx = masked_gradients# *****END OF YOUR CODE (DO NOT DELETE/MODIFY THIS LINE)*****######################################################################## END OF YOUR CODE ########################################################################elif mode =="test": dx = doutreturn dx
np.random.seed(231)x = np.random.randn(10, 10) +10dout = np.random.randn(*x.shape)dropout_param = {'mode': 'train', 'p': 0.2, 'seed': 123}out, cache = dropout_forward(x, dropout_param)dx = dropout_backward(dout, cache)dx_num = eval_numerical_gradient_array(lambda xx: dropout_forward(xx, dropout_param)[0], x, dout)# Error should be around e-10 or less.print('dx relative error: ', rel_error(dx, dx_num))
dx relative error: 5.44560814873387e-11
Inline Question 1:
What happens if we do not divide the values being passed through inverse dropout by p in the dropout layer? Why does that happen?
Answer:
Then we must multiply values with p in test time forwardpassing. But this is not efficient when you prioritize the inference phase performance as like in almost all cases
Fully Connected Networks with Dropout
In the file cs231n/classifiers/fc_net.py, modify your implementation to use dropout. Specifically, if the constructor of the network receives a value that is not 1 for the dropout_keep_ratio parameter, then the net should add a dropout layer immediately after every ReLU nonlinearity. After doing so, run the following to numerically gradient-check your implementation.
from builtins importrangefrom builtins importobjectimport numpy as npfrom ..layers import*from ..layer_utils import*class FullyConnectedNet(object):"""Class for a multi-layer fully connected neural network. Network contains an arbitrary number of hidden layers, ReLU nonlinearities, and a softmax loss function. This will also implement dropout and batch/layer normalization as options. For a network with L layers, the architecture will be {affine - [batch/layer norm] - relu - [dropout]} x (L - 1) - affine - softmax where batch/layer normalization and dropout are optional and the {...} block is repeated L - 1 times. Learnable parameters are stored in the self.params dictionary and will be learned using the Solver class. """def__init__(self, hidden_dims, input_dim=3*32*32, num_classes=10, dropout_keep_ratio=1, normalization=None, reg=0.0, weight_scale=1e-2, dtype=np.float32, seed=None, ):"""Initialize a new FullyConnectedNet. Inputs: - hidden_dims: A list of integers giving the size of each hidden layer. - input_dim: An integer giving the size of the input. - num_classes: An integer giving the number of classes to classify. - dropout_keep_ratio: Scalar between 0 and 1 giving dropout strength. If dropout_keep_ratio=1 then the network should not use dropout at all. - normalization: What type of normalization the network should use. Valid values are "batchnorm", "layernorm", or None for no normalization (the default). - reg: Scalar giving L2 regularization strength. - weight_scale: Scalar giving the standard deviation for random initialization of the weights. - dtype: A numpy datatype object; all computations will be performed using this datatype. float32 is faster but less accurate, so you should use float64 for numeric gradient checking. - seed: If not None, then pass this random seed to the dropout layers. This will make the dropout layers deteriminstic so we can gradient check the model. """self.normalization = normalizationself.use_dropout = dropout_keep_ratio !=1self.reg = regself.num_layers =1+len(hidden_dims)self.dtype = dtypeself.params = {}############################################################################# TODO: Initialize the parameters of the network, storing all values in ## the self.params dictionary. Store weights and biases for the first layer ## in W1 and b1; for the second layer use W2 and b2, etc. Weights should be ## initialized from a normal distribution centered at 0 with standard ## deviation equal to weight_scale. Biases should be initialized to zero. ## ## When using batch normalization, store scale and shift parameters for the ## first layer in gamma1 and beta1; for the second layer use gamma2 and ## beta2, etc. Scale parameters should be initialized to ones and shift ## parameters should be initialized to zeros. ############################################################################## *****START OF YOUR CODE (DO NOT DELETE/MODIFY THIS LINE)***** verbose =Falseif verbose: print('num_layers:', self.num_layers, '\n') len_hidden_dims =len(hidden_dims)for layer_num inrange(1, self.num_layers+1): number_of_nodes =Noneif verbose: print('layer_num:', layer_num)if layer_num ==1: # First Layerif verbose: print('\tfirst_layer')self.params[f"W{layer_num}"] = np.random.normal(0.0, weight_scale, (input_dim, hidden_dims[0]))self.params[f"b{layer_num}"] = np.zeros(hidden_dims[0], )ifself.normalization =="batchnorm":self.params[f"gamma{layer_num}"] = np.ones((hidden_dims[0], ))self.params[f"beta{layer_num}"] = np.zeros((hidden_dims[0], ))elif layer_num ==self.num_layers: #Last Layerif verbose: print('\tlast_layer')self.params[f"W{layer_num}"] = np.random.normal(0.0, weight_scale, (hidden_dims[-1], num_classes))self.params[f"b{layer_num}"] = np.zeros(num_classes, )else: # Hidden Layersif verbose: print('\thidden_layer') hidden_dim_curr = hidden_dims[layer_num-2] hidden_dim_next = hidden_dims[layer_num-1]self.params[f"W{layer_num}"] = np.random.normal(0.0, weight_scale, (hidden_dim_curr, hidden_dim_next))self.params[f"b{layer_num}"] = np.zeros(hidden_dim_next, )ifself.normalization =="batchnorm":self.params[f"gamma{layer_num}"] = np.ones((hidden_dim_next, ))self.params[f"beta{layer_num}"] = np.zeros((hidden_dim_next, ))if verbose: print(f"\tW{layer_num}:", self.params[f"W{layer_num}"].shape)print(f"\tb{layer_num}:", self.params[f"b{layer_num}"].shape)iff"gamma{layer_num}"inself.params:print(f"\tgamma{layer_num}:", self.params[f"gamma{layer_num}"].shape)print(f"\tbeta{layer_num}:", self.params[f"beta{layer_num}"].shape)# *****END OF YOUR CODE (DO NOT DELETE/MODIFY THIS LINE)*****############################################################################# END OF YOUR CODE ############################################################################## When using dropout we need to pass a dropout_param dictionary to each# dropout layer so that the layer knows the dropout probability and the mode# (train / test). You can pass the same dropout_param to each dropout layer.self.dropout_param = {}ifself.use_dropout:self.dropout_param = {"mode": "train", "p": dropout_keep_ratio}if seed isnotNone:self.dropout_param["seed"] = seed# With batch normalization we need to keep track of running means and# variances, so we need to pass a special bn_param object to each batch# normalization layer. You should pass self.bn_params[0] to the forward pass# of the first batch normalization layer, self.bn_params[1] to the forward# pass of the second batch normalization layer, etc.self.bn_params = []ifself.normalization =="batchnorm":self.bn_params = [{"mode": "train"} for i inrange(self.num_layers -1)]ifself.normalization =="layernorm":self.bn_params = [{} for i inrange(self.num_layers -1)]# Cast all parameters to the correct datatype.for k, v inself.params.items():self.params[k] = v.astype(dtype)def loss(self, X, y=None):"""Compute loss and gradient for the fully connected net. Inputs: - X: Array of input data of shape (N, d_1, ..., d_k) - y: Array of labels, of shape (N,). y[i] gives the label for X[i]. Returns: If y is None, then run a test-time forward pass of the model and return: - scores: Array of shape (N, C) giving classification scores, where scores[i, c] is the classification score for X[i] and class c. If y is not None, then run a training-time forward and backward pass and return a tuple of: - loss: Scalar value giving the loss - grads: Dictionary with the same keys as self.params, mapping parameter names to gradients of the loss with respect to those parameters. """ X = X.astype(self.dtype) mode ="test"if y isNoneelse"train"# Set train/test mode for batchnorm params and dropout param since they# behave differently during training and testing.ifself.use_dropout:self.dropout_param["mode"] = modeifself.normalization =="batchnorm":for bn_param inself.bn_params: bn_param["mode"] = mode scores =None############################################################################# TODO: Implement the forward pass for the fully connected net, computing ## the class scores for X and storing them in the scores variable. ## ## When using dropout, you'll need to pass self.dropout_param to each ## dropout forward pass. ## ## When using batch normalization, you'll need to pass self.bn_params[0] to ## the forward pass for the first batch normalization layer, pass ## self.bn_params[1] to the forward pass for the second batch normalization ## layer, etc. ############################################################################## *****START OF YOUR CODE (DO NOT DELETE/MODIFY THIS LINE)***** affine_cache =None bn_cache =None relu_cache =None dropout_cache =None caches = {} input_data = Xfor layer_num inrange(1, self.num_layers): weights =self.params[f"W{layer_num}"] biases =self.params[f"b{layer_num}"] temp_out, affine_cache = affine_forward(input_data, weights, biases)#batch/layer normifself.normalization =="batchnorm": x = temp_out gamma =self.params[f"gamma{layer_num}"] beta =self.params[f"beta{layer_num}"] bn_param =self.bn_params[layer_num-1] temp_out, bn_cache = batchnorm_forward(x, gamma, beta, bn_param) relu_out, relu_cache = relu_forward(temp_out)#dropout input_data = relu_out cache = (affine_cache, bn_cache, relu_cache, dropout_cache) caches[f"cache{layer_num}"] = cache layer_num =self.num_layers weights =self.params[f"W{layer_num}"] biases =self.params[f"b{layer_num}"] affine_out, affine_cache = affine_forward(input_data, weights, biases) caches[f"cache{layer_num}"] = affine_cache scores = affine_out# *****END OF YOUR CODE (DO NOT DELETE/MODIFY THIS LINE)*****############################################################################# END OF YOUR CODE ############################################################################## If test mode return early.if mode =="test":return scores loss, grads =0.0, {}############################################################################# TODO: Implement the backward pass for the fully connected net. Store the ## loss in the loss variable and gradients in the grads dictionary. Compute ## data loss using softmax, and make sure that grads[k] holds the gradients ## for self.params[k]. Don't forget to add L2 regularization! ## ## When using batch/layer normalization, you don't need to regularize the ## scale and shift parameters. ## ## NOTE: To ensure that your implementation matches ours and you pass the ## automated tests, make sure that your L2 regularization includes a factor ## of 0.5 to simplify the expression for the gradient. ############################################################################## *****START OF YOUR CODE (DO NOT DELETE/MODIFY THIS LINE)***** loss, dout = softmax_loss(scores, y) layer_num =self.num_layers w =self.params[f"W{layer_num}"] cache = caches[f"cache{layer_num}"] dx, dw, db = affine_backward(dout, cache) grads[f"W{layer_num}"] = dw + (self.reg * w) grads[f"b{layer_num}"] = db loss +=0.5*self.reg * (np.sum(w * w))for layer_num inrange(self.num_layers-1, 0, -1): cache = caches[f"cache{layer_num}"] w =self.params[f"W{layer_num}"] affine_cache, bn_cache, relu_cache, dropout_cache = cache temp_dout = relu_backward(dx, relu_cache)ifself.normalization =="batchnorm": temp_dout, dgamma, dbeta = batchnorm_backward_alt(temp_dout, bn_cache) dx, dw, db = affine_backward(temp_dout, affine_cache) grads[f"W{layer_num}"] = dw + (self.reg *self.params[f"W{layer_num}"]) grads[f"b{layer_num}"] = dbifself.normalization =="batchnorm": grads[f"gamma{layer_num}"] = dgamma grads[f"beta{layer_num}"] = dbeta loss +=0.5*self.reg * (np.sum(w * w))# *****END OF YOUR CODE (DO NOT DELETE/MODIFY THIS LINE)*****############################################################################# END OF YOUR CODE #############################################################################return loss, grads
np.random.seed(231)N, D, H1, H2, C =2, 15, 20, 30, 10X = np.random.randn(N, D)y = np.random.randint(C, size=(N,))for dropout_keep_ratio in [1, 0.75, 0.5]:print('Running check with dropout = ', dropout_keep_ratio) model = FullyConnectedNet( [H1, H2], input_dim=D, num_classes=C, weight_scale=5e-2, dtype=np.float64, dropout_keep_ratio=dropout_keep_ratio, seed=123 ) loss, grads = model.loss(X, y)print('Initial loss: ', loss)# Relative errors should be around e-6 or less.# Note that it's fine if for dropout_keep_ratio=1 you have W2 error be on the order of e-5.for name insorted(grads): f =lambda _: model.loss(X, y)[0] grad_num = eval_numerical_gradient(f, model.params[name], verbose=False, h=1e-5)print('%s relative error: %.2e'% (name, rel_error(grad_num, grads[name])))print()
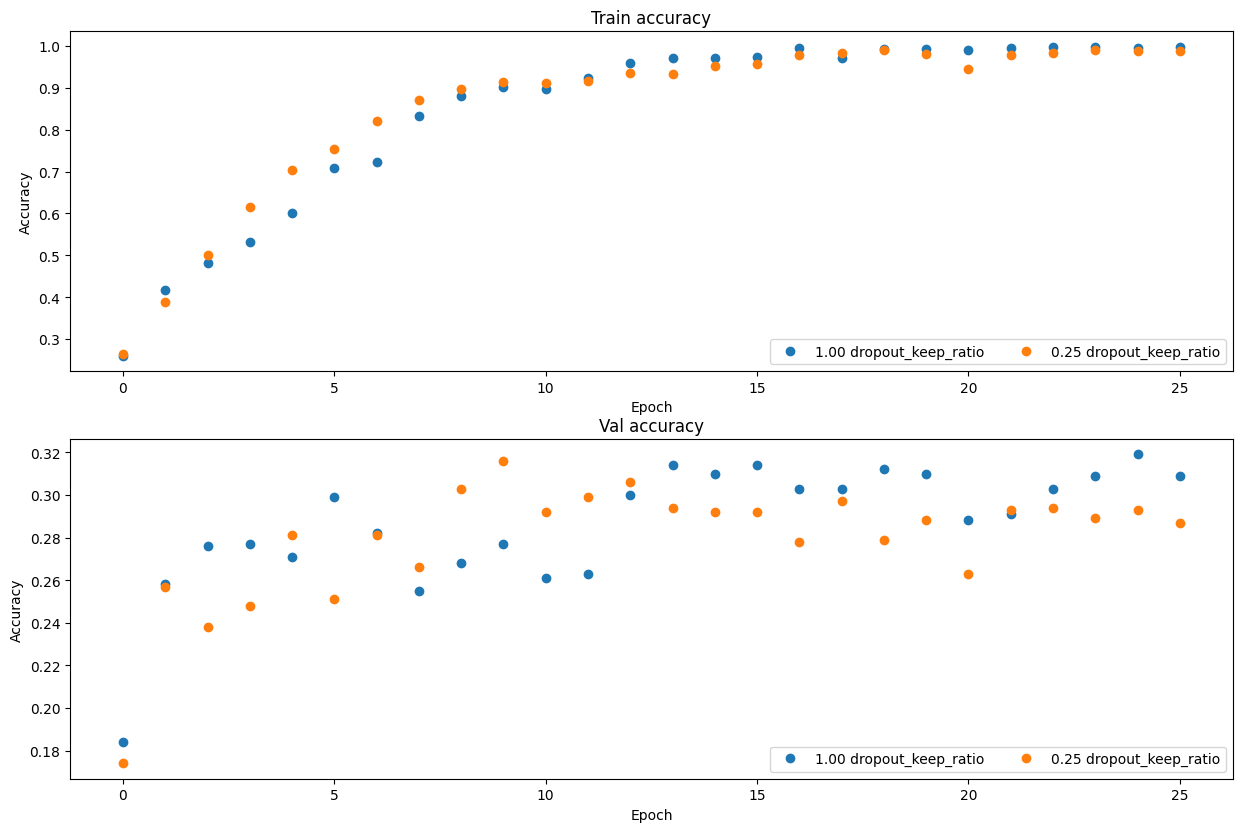
As an experiment, we will train a pair of two-layer networks on 500 training examples: one will use no dropout, and one will use a keep probability of 0.25. We will then visualize the training and validation accuracies of the two networks over time.
# Train two identical nets, one with dropout and one without.np.random.seed(231)num_train =500small_data = {'X_train': data['X_train'][:num_train],'y_train': data['y_train'][:num_train],'X_val': data['X_val'],'y_val': data['y_val'],}solvers = {}dropout_choices = [1, 0.25]for dropout_keep_ratio in dropout_choices: model = FullyConnectedNet( [500], dropout_keep_ratio=dropout_keep_ratio )print(dropout_keep_ratio) solver = Solver( model, small_data, num_epochs=25, batch_size=100, update_rule='adam', optim_config={'learning_rate': 5e-4,}, verbose=True, print_every=100 ) solver.train() solvers[dropout_keep_ratio] = solverprint()